



How Discord Supercharges Network Disks for Extreme Low Latency
Posted by jpluimers on 2024/12/27
A while ago there was an interesting point of using tiered md to both obtain low read latency and write safety on the Google Cloud Platform in [Wayback/Archive] How Discord Supercharges Network Disks for Extreme Low Latency
It is an interesting approach to universally tune performance within the sketched boundaries, but raised some questions as their aim was improving ScyllaDB performance and Unix-like platforms on Google Cloud Platform can supports ZFS.
In this case Discord wanted to improve their ScyllaDB that was already read/written from GCP Persistent Storage and used tiered md to improve that.
Isotopp asked himself why ScyllaDB replication had not been used and I invited Discord to comment on that:
- [Wayback/Archive] Kris on Twitter: “I don’t know @ScyllaDB, and I have questions. Does the database not have an internal replication mechanism to handle node failure? If it does, why not use that and do this RAID stacking instead?”
- [Wayback/Archive] Kris on Twitter: “Their documentation says they do consistent hashing with internal shard replication. I get Discord’s RAID dance even less. What is the performance impact of a disk loss in ScyllaDB for n=3, read cl 1 and write cl 3? Why even bother with remote storage?
docs.scylladb.com/stable/architecture/architecture-fault-tolerance.html“ - [Wayback/Archive] Jeroen Wiert Pluimers on Twitter: “@isotopp I wonder about that too. Care to comment on that @discord?”

Bobby wondered about ZFS and indeed that is somewhere on the wish list already and kind of possible when you throw iSCSI in the middle:
- [Wayback/Archive] bobby on Twitter: “@tqbf crazy how this isn’t even zfs” / Twitter
- [Wayback/Archive] Allan Jude on Twitter: “@palm_beach_m @tqbf We have discussed this for ZFS. With the new vdev properties feature, it makes it pretty easy to configure the “hint” about which one to read. Even so far as for a metro-net setup, to say “if you are host A, use side A, host B use side B””
- [Wayback/Archive] Bob Hannent on Twitter: “@allanjude @palm_beach_m @tqbf I had a system which had a RAID5 where one of the SAS SSDs failed, and I had to wait for the replacement drive as it was weird (600GB) but didn’t want to sit with it degraded. So, I added a fast iSCSI disk of the same size temporarily and when the replacement arrived swapped it.”
- [Wayback/Archive] Telecom Destruct Bunny on Twitter: “@allanjude @palm_beach_m @tqbf i love the ZFS special devices feature. i tune each pool to pick the balance of file sizes to go on fast SSD or slower HDD.
forum.level1techs.com/t/zfs-metadata-special-device-z/159954“
I liked the article and questions as it taught me a lot of things I was only partially aware of.
- [Wayback/Archive] Thomas H. Ptacek on Twitter: “Here’s something you can do with Linux software raid: make a RAID0 of SSDs, and then a RAID1 of the RAID0 and a high-latency network-attached drive, and hint to the kernel to read from the fast RAID0 half of the RAID1. “
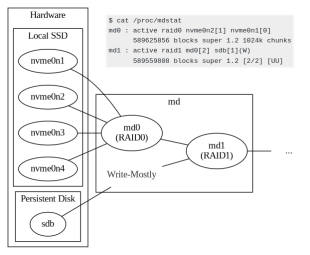
- [Wayback/Archive] Thomas H. Ptacek on Twitter: “Current status:”
[Wayback/Archive] Willy Wonka & the Chocolate Factory – Pure Imagination Scene (4/10) | Movieclips – YouTube
- [Wayback/Archive] Daniel Raloff on Twitter: “@dvessey @tqbf From the linked article, they were already using network attached storage for both reads and writes. So this system gives them ~the same write performance, but reads are now a couple orders of magnitude faster” / Twitter
- [Wayback/Archive] Thomas H. Ptacek on Twitter: “Current status:”
Via:
- [Wayback/Archive] kurtle 🐢 on Twitter: “Excellent, excellent post about using md for clever disk setups.”
--jeroen
PS: (evening of 20241227) – Kris added two more comments in [Wayback/Archive] Kris: “Conclusion In retrospect, disk…” – Infosec Exchange
Conclusion
In retrospect, disk latency should have been an obvious concern early on in our database deployments. The world of cloud computing causes so many systems to behave in ways that are nothing like their physical data center counterparts.Manically giggling, exiting stage left
Below a certain database query rate, disk latency isn’t noticeable
That is actually nonsense. It is not the query rate that kills you, it’s the wait.
You have wait when waiting for data to be read from disk, and you have that at any query rate.
The critical metric is actually Working Set Size, which must be smaller than available memory. You can have data even in S3, if you have enough cache in front so that queries never read S3 (+ a cache warmup procedure on start).


Leave a comment