



It looks like AVX can be a curse most of the times. Below are some (many) links that lead me to this conclusion, based on a thread started by Kelly Sommers.
My conclusion
Running AVX instructions will affect the processor frequency, which means that non-AVX code will slow down, so you will only benefit when the gain of using AVX code outweighs the non-AVX loss on anything running on that processor in the same time frame.
In practice, this means you need to long term gain from AVX on many cores. If you don’t, then the performance penalty on all cores, including the initial AVX performance, will degrade, often a lot (dozens of %).
Tweets and pages linked by them
- [WayBack] Kelly Sommers on Twitter: “So here’s a real question. What does Amazon and Microsoft and other kubernetes cloud services do to prevent your containers from losing 11ghz of performance because someone deployed some AVX optimized algorithm on the same host?”
- [WayBack] Jeroen Pluimers on Twitter: “Where do I learn more on side effects of AVX?… “
- [WayBack] Kelly Sommers on Twitter: “Not the greatest link but the quickest one I found lol https://t.co/NUvEl1CEp5… “
- [WayBack] E-class CPUs down clock when AVX is in the execution stack? Is this true, if so why would it?
- The Core i7 processors that are referred to as “Haswell-E” and “Broadwell-E” are minor variants of the Xeon E5 v3 “Haswell-EP” and Xeon E5 v4 “Broadwell-EP” processors. These have lower “maximum Turbo” frequencies for each core count when 256-bit registers are being used.
- Certain AVX workloads may run at lower peak turbo frequencies, or drop below the Non-AVX Base Frequency of the SKU. This type of behavior is due to power, thermal, and electrical constraints.
- [WayBack] PDF: Optimizing Performance with Intel® Advanced Vector Extensions
- [WayBack] E-class CPUs down clock when AVX is in the execution stack? Is this true, if so why would it?
- [WayBack] 🤓science_dot on Twitter: “https://t.co/YAZWbuo9Mn contains the frequency tables for Skylake Xeon for non-AVX, AVX2 and AVX-512. There are nuances that don’t fit into a tweet… (#ImIntel)… https://t.co/vSRFSd9GAb”
- [WayBack] Phil Dennis-Jordan on Twitter: “Basically, PC games don’t use AVX for this exact reason. AVX is great if >90% of your CPU time is spent in AVX code across all cores, for long-lasting workloads. Which pretty much means it gets used for HPC and maybe CPU-intensive content creation and that’s about it.… https://t.co/HMfmhPeSHH”
- [WayBack] Phil Dennis-Jordan on Twitter: “As soon as you use an AVX instruction on recent Intel CPUs, you trip its protective AVX clock circuitry. This means that for the next N milliseconds, it’s limited to whatever the rated maximum AVX clock rate is.… https://t.co/2poSaQDmXF”
- [WayBack] Phil Dennis-Jordan on Twitter: “It doesn’t matter if you’re pegging the core for long running calculations or just briefly switched to AVX because it has a convenient instruction. For this defined amount of time, anything running will be subject to the AVX clock limit.… https://t.co/ZxgXAzbu3R”
- [WayBack] svacko on Twitter: “also check wikichip that has perfect resources on this AVX/AVX2/AVX512 downscaling https://t.co/1nn3Wn1dO1 i was also pretty shocked when i found this as we are massively using AVX2 in our shop.. i think there are no GHz guarantees, the clouders guarantees you only vCPUs…… https://t.co/UwDTsmWT3W”
- [WayBack] Frequency Behavior – Intel – WikiChip: The Frequency Behavior of Intel’s CPUs is complex and is governed by multiple mechanisms that perform dynamic frequency scaling based on the available headroom.
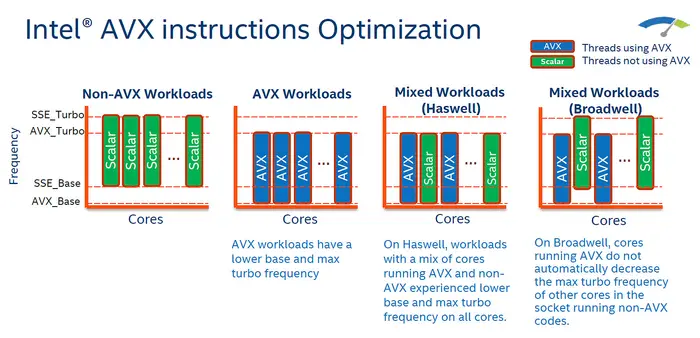

- [WayBack] Frequency Behavior – Intel – WikiChip: The Frequency Behavior of Intel’s CPUs is complex and is governed by multiple mechanisms that perform dynamic frequency scaling based on the available headroom.
- [WayBack] Ben Adams on Twitter: “Cloudflare did write up about AVX2: On the dangers of Intel’s frequency scaling https://t.co/JYbhjTwiD0… “
- [WayBack] On the dangers of Intel’s frequency scaling: While I was writing the post comparing the new Qualcomm server chip, Centriq, to our current stock of Intel Skylake-based Xeons, I noticed a disturbing phenomena. When benchmarking OpenSSL 1.1.1dev, I discovered that the performance of the cipher ChaCha20-Poly1305 does not scale very well.
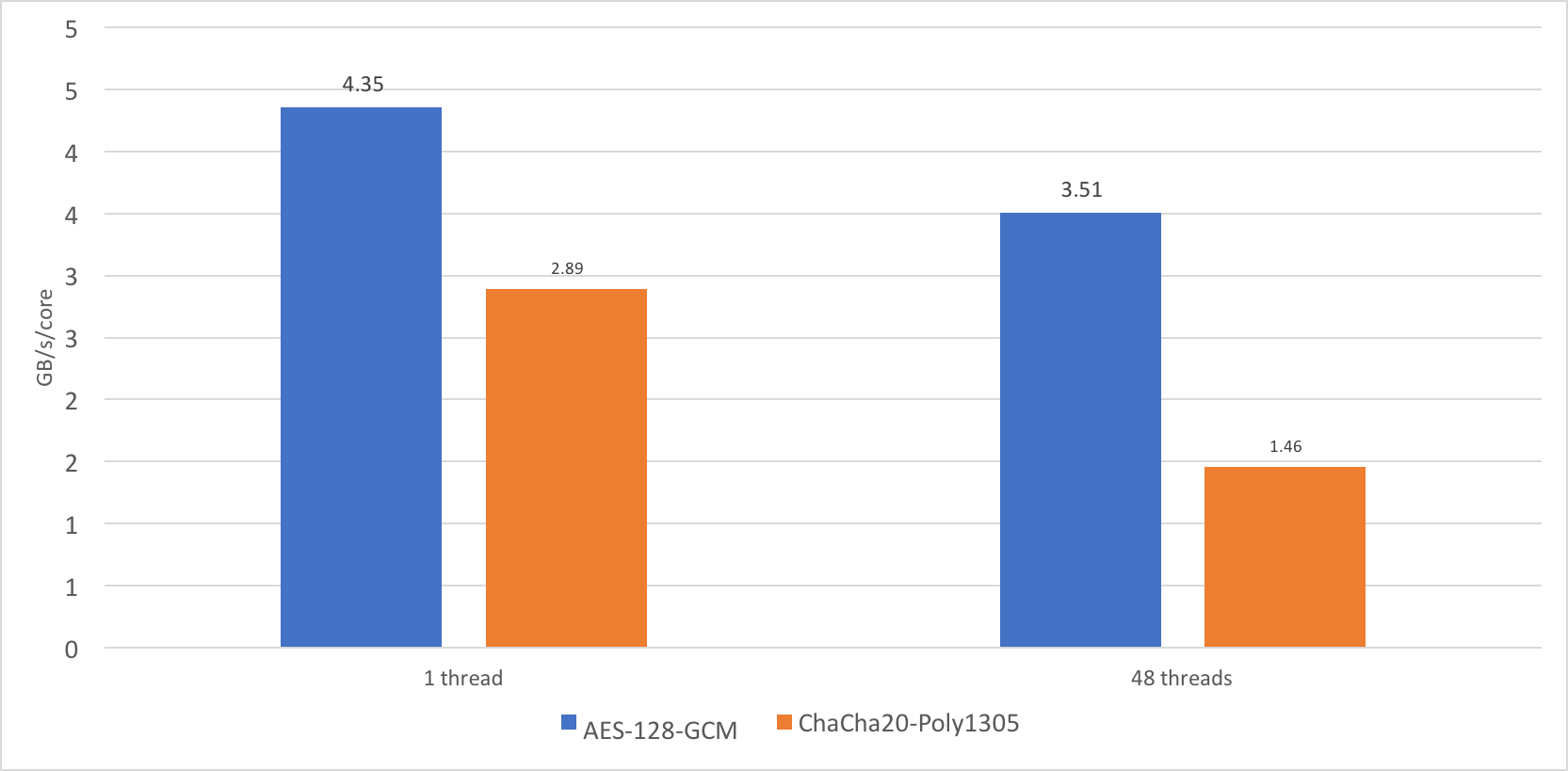
- [WayBack] On the dangers of Intel’s frequency scaling: While I was writing the post comparing the new Qualcomm server chip, Centriq, to our current stock of Intel Skylake-based Xeons, I noticed a disturbing phenomena. When benchmarking OpenSSL 1.1.1dev, I discovered that the performance of the cipher ChaCha20-Poly1305 does not scale very well.
- [WayBack] Vlad Krasnov on Twitter: “https://t.co/gtcQHjJFLQ When compiling with -mavx512dq it runs 25% on a Gold with 40 threads On Silver with 24 threads: ~30% slower… https://t.co/UmwyYY0ISR”
- [WayBack] Ryan Zezeski on Twitter: “I haven’t done much reading (or any testing) about this myself, but I did find this summary interesting: https://t.co/Yjsh8kB789… https://t.co/MZqBXlkiHz”
- [WayBack] avx_sigh.md · GitHub
why doesn’t radfft support AVX on PC?
- The short version is that unless you’re planning to run AVX-intensive code on that core for at least the next 10ms or so, you are completely shooting yourself in the foot by using AVX float.A complex RADFFT at N=2048 (relevant size for Bink Audio, Miles sometimes uses larger FFTs) takes about 19k cycles when computed 128b-wide without FMAs. That means that the actual FFT runs and completes long before we ever get the higher power license grant, and then when we do get the higher power license, all we’ve done is docked the core frequency by about 15% (25%+ when using AVX-512) for the next couple milliseconds, when somebody else’s code runs.That’s a Really Bad Thing for middleware to be doing, so we don’t.
- These older CPUs are somewhat faster to grant the higher power license level (but still on the order of 150k cycles), but if there is even one core using AVX code, all cores (well, everything on the same package if you’re in a multi-socket CPU system) get limited to the max AVX frequency.And they don’t seem to have the “light” vs. “heavy” distinction either. Use anything 256b wide, even a single instruction, and you’re docking the max turbo for all cores for the next couple milliseconds.That’s an even worse thing for middleware to be doing, so again, we try not to.
- [WayBack] avx_sigh.md · GitHub
- [WayBack] Ben Higgins on Twitter: “I’d have to hunt down the specifics but we saw a perf regression we attributed to AVX512 additions added to glibc. Disabling the AVX512 version improved perf for our app.… https://t.co/IZIzuBO2F8”
- [WayBack] Bartek Ogryczak on Twitter: “TIL, thanks for mentioning this. Intel is saying “workaround: none, fix: none” 😱 https://t.co/6BVJqV8rff… https://t.co/STEbs6M2tK”
- [WayBack] Ben Higgins on Twitter: “My colleagues tracked it down to an avx512-specific variant of memmove in glibc, despite not calling it very often we saw a big speedup on skylake when we stopped using the avx512 version.… https://t.co/vz2u8dCKbX”
- [WayBack] Trent Lloyd 🦆on Twitter: “Though not quite the same issue, this bug has some really interesting insight into reasons you can kill performance using various variants of SSE/AVX… https://t.co/pNghRVJZO0 – was fascinating to me.… https://t.co/b3jb9WFWne”
- [WayBack] Bug #1663280 “Serious performance degradation of math functions” : Bugs : glibc package : Ubuntu
- [WayBack] Trent Lloyd 🦆 on Twitter: “Super short version was that mixing SSE (128-bit) and AVX-256 which uses the same registers but “extended” to 256bits on some CPUs requires the CPU to save the register state between calls. glibc and the application were interchangeably using SSE/AVX which ruined performance 4x+… https://t.co/SlWRgEHtMF”
- [WayBack] Daniel Lemire on Twitter: “… this applies only to older Intel CPUs. The description is somewhat misleading.… “
- [WayBack] Daniel Lemire on Twitter: “AMD processors and Intel processors from Skylake and up are unaffected. It is definitively not the case that it affects all AVX-capable processors. And I would argue that the code was poorly crafted to begin with. Have you looked at it?… https://t.co/GMXCYDSjMG”
- [WayBack] Trent Lloyd 🦆 on Twitter: “Yeah I left that detail out on account of trying to being short but that was probably a disservice. It is quite relevant that I t’s CPU specific and part of why it can be hard to reproduce the issue for some in that specific case.… https://t.co/N1w9FPNeKQ”
Kelly raised a bunch of interesting questions and remarks because of the above:
- [WayBack] Kelly Sommers on Twitter: “If thermal heat is a huge issue with many core processors and turbo boost clock speeds why don’t we just have smaller processors with multiple processors scattered across the motherboard with individual cooling? It makes no sense to turbo boost 1 of 10 cores.”
- [WayBack] Kelly Sommers on Twitter: “Here’s what I consider a real problem about multi-tenant or multi-workload containerization like Kubernetes Let’s say you deploy a bunch of containers to some nodes. I deploy a HTTP server that is highly optimized with AVX and all the other cores down clock to prevent melting.”
- [WayBack] Kelly Sommers on Twitter: “You get paged at 3am because I just ripped 1ghz multiplied by 11 and stole 11ghz worth of performance from the rest of the system.”
- [WayBack] Kelly Sommers on Twitter: “So here’s a real question. What does Amazon and Microsoft and other kubernetes cloud services do to prevent your containers from losing 11ghz of performance because someone deployed some AVX optimized algorithm on the same host?”
- [WayBack] Kelly Sommers on Twitter: “How do and how will containerized orchestration systems like Kubernetes enforce isolation from the tricks Intel CPU’s do to prevent from melting when highly optimized code is running in a tight loop?”
- [WayBack] Kelly Sommers on Twitter: “I could just start deploying really small containers all over Amazon and Azure requesting very cheap 1 milli CPU resources in Kubernetes and have a tight AVX loop and trip the Intel thermal kick stand and make all that hosts and your containers drop significantly in performance.”
- [WayBack] Kelly Sommers on Twitter: “If you have a Kubernetes cluster or you are a cloud provider of Kubernetes like Amazon or Azure and have turbo boost enabled or SSE/AVX enabled it seems to me you’re vulnerable to attacks that cripple all CPU cores on the system.”
- [WayBack] Kelly Sommers on Twitter: “Feels to me CPU’s were designed for single threaded performance and then we slapped 8, 10, 12, 16 of them together as cores into a single package and it started to get too hot so now the competing designs fight against each other. It’s no longer a wholistic thought out design.”
- [WayBack] Kelly Sommers on Twitter: “Noisey neighbours has always been a problem, mostly due to CPU cache and memory bandwidth sharing but more than ever CPU’s are designed in such a way it’s easy to exploit it’s thermal protections in a heavy handed way that affects all cores very significantly.”
- [WayBack] Kelly Sommers on Twitter: “Another similar attack would be code designed to cause CPU instruction prediction pipelines to invalidate constantly affecting all code run on a CPU core. This is a much harder attack than the AVX one. You could in theory continuously flush the deep instruction pipeline.”
I collected the above links because of [WayBack] GitHub – maximmasiutin/FastMM4-AVX: FastMM4 fork with AVX support and multi-threaded enhancements (faster locking), where it is unclear which parts of the gains are because of AVX and which parts are because of other optimizations. It looks like that under heavy loads on data center like conditions, the total gain is about 30%. The loss for traditional processing there has not been measured, but from the above my estimate it is at least 20%.
Full tweets below.


