



In this day and age, web sites with delivery back-ends still have Unicode issues: at least @Woonveilig, @Medireva and @PostNL still have trouble
Posted by jpluimers on 2022/02/09
Nowadays, some 35 years after the first Unicode ideas got drafted and 30+ years after the Unicode Consortium saw the light, UTF-8 is served my more than 95% of the web as shown in yesterday’s post UTF-8 web adoption is huge, closing 100%, but only soured up since around 2006..
I mentioned this:
It means that nowadays there is a very small chance you will see mangled characters (what Japanese call mojibake) when you’re surfing the web.
Serving UTF8 does not mean no unicode problems.
Below are some issues that happened not too long ago and still happen. I have reported them to all parties involved through web-care, but no response whatsoever, and this is bad: Unicode support beyond basic ASCII for the below systems are still broken even for relatively simple non-ASCII characters based in diacritics decorating a standard ASCII character.
Yes, I know the realm of encoding and code pages is a mess, especially when handling data in multiple layers of an application stack. That’s why I wrote this post in the first place, and have a whole encoding category of blog posts plus a Mojibake subset.
Woonveilig back-end serving non-ASCII while the front-end limits to an ASCII-subset
This is the series of tweets:
- [Archive.is] Jeroen Wiert Pluimers on Twitter: “Grappig als je op de shop van @WoonVeilig een juiste postcode en huisnummer invult, maar je straatnaam een diakriet zoals een trema of accent bevat.
"De Straatnaam bevat onjuiste tekens."Nee hoor, jullie front-end snapt jullie back-end response niet. … “

- [Archive.is] Jeroen Wiert Pluimers on Twitter: “Wat andere straatnamen die ook mis gaan staan in … Kennelijk zijn Woonveilig en @MediReva niet alleen met systemen die problemen hebben met diakrieten in straatnamen.”
- [Wayback] Stempassen Rotterdam foutgedrukt: ä, é en ï verdwenen – Rijnmond
Een deel van de Rotterdamse stempassen voor het Oekraïne-referendum is foutgedrukt. Bij de straatnamen en locaties van de stembureaus zijn letters als de ï, ä en de é veranderd in onleesbare tekens.
De zogenoemde diakrieten, zoals het trema en het accent aigu, zijn verkeerd afgedrukt. In totaal zijn 13.558 stempassen mislukt.
Onder andere bij Buurthuis De Mozaïek, Wijkcentrum Oriënt, Pniël en basisschool Minister Marga Klompé zijn de tekens verdwenen. Ook Isaäc Hubertstraat, Rösener Manzstraat en Hammarskjöldplaats missen hun diakrieten.
- [Wayback] Stempassen Rotterdam foutgedrukt: ä, é en ï verdwenen – Rijnmond
- [Archive.is] Jeroen Wiert Pluimers on Twitter: “Volgens het BAG (Basisregistratie Adressen en Gebouwen) is heel UTF-8 mogelijk voor straatnamen, dus horen systemen dat gewoon aan te kunnen en daarop in de hele keten getest te worden. De pagina .. bevat een kort stukje uit … hierover.”
I summarised what happened in Dutch at [Wayback/Archive.is] Woonveilig postcode check geeft straatnaam met diakriet, maar user-interface validatie keurt dat af.:
Postcode/huisnummer URL:[Wayback/Archive.is] https://www.woonveilig.nl/engine/woonveilig__website__shop__order__address_c?building=1&zip=2717+BAValidation result:{"street":"C\u00e9sar Franckrode","houseNumber":1,"houseNumberAddition":"","postcode":"2717BA","city":"Zoetermeer","municipality":"Zoetermeer","province":"Zuid-Holland","rdX":91967,"rdY":453852,"latitude":52.06936633,"longitude":4.46788106,"bagNumberDesignationId":"0637200000256226","bagAddressableObjectId":"0637010000256227","addressType":"building","purposes":["residency"],"surfaceArea":103,"houseNumberAdditions":[""]}Validation script URL:Validation script fragment:this.setStreetNameBlur = function(element_o) { var valid_b = this.setValidationByRegExp(element_o, '^[A-Za-z\\. ]+$', 'De Straatnaam bevat onjuiste tekens.'); if (valid_b) element_o.value = element_o.value.charAt(0).toUpperCase() + element_o.value.toLowerCase().substr(1);
In other words: the back-end correctly returns Unicode, but the frontend limits input to uppercase A-Z, lowercase a-z, period and space. Inconvenient, because technically speaking, Dutch street names are allowed to use any printable Unicode code point.
An example is again in Zoetermeer with the valid street César Franckrode (not my street: I don’t live in Zoetermeer), which the back-end correctly returns as escaped Unicode characters and also ends up with "De Straatnaam bevat onjuiste tekens." in the user interface. [Wayback/Archive.is] www.woonveilig.nl/engine/woonveilig__website__shop__order__address_c?building=1&zip=2717+BA
{"street":"C\u00e9sar Franckrode","houseNumber":1,"houseNumberAddition":"","postcode":"2717BA","city":"Zoetermeer","municipality":"Zoetermeer","province":"Zuid-Holland","rdX":91967,"rdY":453852,"latitude":52.06936633,"longitude":4.46788106,"bagNumberDesignationId":"0637200000256226","bagAddressableObjectId":"0637010000256227","addressType":"building","purposes":["residency"],"surfaceArea":103,"houseNumberAdditions":[""]}
Failing not just with non-ASCII printables
The same results for a different street, but in the city of Utrecht. Back in the days, the city replaced spaces by apostrophes: [Wayback/Archive.is] www.woonveilig.nl/engine/woonveilig__website__shop__order__address_c?building=1&zip=3543+EL
{"street":"Nat'King'Colestraat","houseNumber":1,"houseNumberAddition":"","postcode":"3543EL","city":"Utrecht","municipality":"Utrecht","province":"Utrecht","rdX":131693,"rdY":457113,"latitude":52.1017777,"longitude":5.04704835,"bagNumberDesignationId":"0344200000183532","bagAddressableObjectId":"0344010000180443","addressType":"building","purposes":["residency"],"surfaceArea":142,"houseNumberAdditions":[""]}
You guessed it: "De Straatnaam bevat onjuiste tekens."
Where Utrecht probably tried to avoid spaces in a street name thereby offending late Nat King Cole and his family by renaming him into Nat’King’Cole (no high hopes that WordPress refrains from messing with the apostrophes here). The sign with the street name was correct though: the people making it did have sense. After a complaint the street name was spelled incorrectly and didn’t match the signage, the city council indicated they would change the signage. [Archive.is] Google Street View indicated that in 2015 this had not happened yet:
Nat King Colestraat signage in Utrecht which on-line incorrectly is named Nat’King’Colestraat

Basically Utrecht traded a space problem with a quoting problem, waiting for a system that correctly works aruond the quoting problem. That will be a challenge, for instance with a street name like “d'Argtagnanstraat“. In that sense, Almere does better with [Wayback] Postcode Nat King Colestraat in Almere – Postcode bij adres.
Note that when writing this, I knew that there was a [Wayback] “d'Argtagnanstraat” in Wezet, Belgium, but missed that there was a [Wayback] “d'Artagnanlaan” in Maastricht, The Netherlands: [Wayback] Postcode d’Artagnanlaan in Maastricht – Postcode bij adres
- [Archive.is] Joel Haasnoot on Twitter: “Ach, anno 2011 vond Gemeente Utrecht nog steeds dat het de “Nat’King’Colestraat” is (staat nog steeds zo, zonder spaties in BAG). Het bordje heeft (had?) wel spaties. Bij een klacht gaf de gemeente aan dat ze het bordje gingen aanpassen…… https://t.co/qeZJwujo3W”
- [Archive.is] Joel Haasnoot on Twitter: “Het stond nou eenmaal zo in het straatnamenbesluit 🙈… “
- [Archive.is] straatnamen on Twitter: “Ah, genoemd naar de beroemde jazzmuzikant Nat’King’Cole zeker? ;-)… “
- [Archive.is] Joel Haasnoot on Twitter: “Het stond nou eenmaal zo in het straatnamenbesluit 🙈… “
- [Archive.is] Jeroen Wiert Pluimers on Twitter: “Spatieprobleem omzeild. Quoteprobleem geïntroduceerd. Een soort ducttape, maar dan als permanente oplossing.… “
- [Archive.is] straatnamen on Twitter: “Het wachten is nu op systemen die de quotes in die straatnaam dan weer gaan escapen. ;-)… “
- [Archive.is] Jeroen Wiert Pluimers on Twitter: “Dat wordt dan leuk als er een d’Artagnanstraat komt.… “
- [Archive.is] Jeroen Wiert Pluimers on Twitter: “Almere doet dat beter.… “
- [Archive.is] straatnamen on Twitter: “Ah, genoemd naar de beroemde jazzmuzikant Nat’King’Cole zeker? ;-)… “
- [Archive.is] Jeroen Wiert Pluimers on Twitter: “Raad trouwens eens wat de @WoonVeilig front-end van jouw straatnaam maakt? De JSON van de back-end is correct: … “
Woonveilig mangles even more
Of course the above is not the only street name problem where the front-end disagrees with the back-end. The JavaScript front-end code forces the first letter of of the street name to me uppercase and everything else to be owercase, even if the back-end returned it correctly, or the user filled it in correctly.
In many cases, this does not hold, especially with street names containing spaces. An example with another street name in Zoetermeer is [Wayback/Archive.is] www.woonveilig.nl/engine/woonveilig__website__shop__order__address_c?building=150&zip=2713+RD:
{"street":"Van Leeuwenhoeklaan","houseNumber":150,"houseNumberAddition":"","postcode":"2713RD","city":"Zoetermeer","municipality":"Zoetermeer","province":"Zuid-Holland","rdX":93134,"rdY":452495,"latitude":52.05730863,"longitude":4.48514815,"bagNumberDesignationId":"0637200000209394","bagAddressableObjectId":"0637010000209395","addressType":"building","purposes":["residency"],"surfaceArea":79,"houseNumberAdditions":[""]}
The user interface incorrectly morphes this into “Van leeuwenhoeklaan” (note the lowercase l instead of the uppercase L): [Archive.is] Jeroen Wiert Pluimers on Twitter: “Inderdaad: “De Straatnaam bevat onjuiste tekens.”. Het kan nog gekker. … wat netjes “Van Leeuwenhoeklaan” en nummer “150” teruggeeft, dat wordt natuurlijk… Inderdaad, geen huisnummer en de L wordt lowercase: “Van Leeuwenhoeklaan”… “

Medireva -> PostNL export
I tried the various tables with encoding issues from Mojibake – Wikipedia, but had a hard time finding the cause for this one:
[Archive.is] Jeroen Wiert Pluimers on Twitter: “Still need to figure out what went wrong here between the @MediReva and @PostNL systems where “PYRENEEËN” on the medireva side (including package label) becomes “PYRENEEÓN” on the PostNL side. Luckily the postal code and house number are correct, so delivery is OK.… “
At first I thought the Ë (U+00CB) to Ó (U+00D3) mapping is odd as it does not match with any of the popular character sets:
- Ë – Wikipedia
Character information Preview Ë ë Unicode name LATIN CAPITAL LETTER E WITH DIAERESIS LATIN SMALL LETTER E WITH DIAERESIS Encodings decimal hex decimal hex Unicode 203 U+00CB 235 U+00EB UTF-8 195 139 C3 8B 195 171 C3 AB Numeric character reference Ë Ë ë ë Named character reference Ë ë Windows 1252; ISO 8859–1, 2, 3, 4, 9, 10, 14, 15, 16 203 CB 235 EB - Ó – Wikipedia
Character information Preview Ó ó Unicode name LATIN CAPITAL LETTER O WITH ACUTE LATIN SMALL LETTER O WITH ACUTE Encodings decimal hex decimal hex Unicode 211 U+00D3 243 U+00F3 UTF-8 195 147 C3 93 195 179 C3 B3 Numeric character reference Ó Ó ó ó Named character reference Ó ó EBCDIC family 238 EE 206 CE Windows 1252; ISO 8859–1/2/3/9/10/13/14/15/16 211 D3 243 F3
From the above tables, I concluded I was basically looking for character sets that had either:
Ë(U+00CB) at code point0xD3in stead of0xCBÓ(U+00D3) at code point0xCBin stead of0xD3
Then I realised this might be based on some old software with DOS or Windows heritage dating back to DOS code pages.
In Western Europe, during the DOS age, both Code page 850 and Code page 858 were popular. Code page 858 basically is codepage 850 where codepoint 0xD5 replaced by the € Euro currency sign.
On Windows the most popular code pages was ISO 8859-1 (before the introduction of the Euro currency), then became ISO 8859-15 after the Euro currency was introduced on 2002-01-01 and on Windows has a kind of superset as Windows 1252. The differences between these code pages are as follows:
80 82 83 84 85 86 87 88 89 8A 8B 8C 8E 91 92 93 94 95 96 97 98 99 9A 9B 9C 9E 9F A4 A6 A8 B4 B8 BC BD BE 8859-1 N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A ¤
00164¦
00a6¨
00A8´
00B4¸
00B8¼
00BC½
00BD¾
00BE8859-15 N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A €
20ACŠ
0160š
0161Ž
017Dž
017EŒ
0152œ
0153Ÿ
0178Windows 1252 €
20AC‚
201Aƒ
0192„
201E…
2026†
2020‡
2021ˆ
02C6‰
2030Š
0160‹
2039Œ
0152Ž
017D‘
2018’
2019“
201C”
201D•
2022–
2013—
2014˜
02DC™
2122š
0161›
203Aœ
0153ž
017EŸ
0178¤
0164¦
00A6¨
00A8´
00B4¸
00B8¼
00BC½
00BD¾
00BE
Note that various columns are missing as they have the same codepoints in all three code pages.
For non-Unicode software on Windows, code page Windows 1252 still is the most popular one. But what if the underlying software was older and assumed a DOS code page, or was historically forced to use a DOS code page?
Bingo: both Code page 850 and Code page 858 have Ë ad codepoint 0xD3 whereas Widows 1252, ISO 8859-1 and ISO 8859-15 had it at 0xCB. You see that Ë is at position 0xD3 in the below tables having Unicode code point U+00CB:
Code page 850 _0 _1 _2 _3 _4 _5 _6 _7 _8 _9 _A _B _C _D _E _F 8_
128Ç
00C7ü
00FCé
00E9â
00E2ä
00E4à
00E0å
00E5ç
00E7ê
00EAë
00EBè
00E8ï
00EFî
00EEì
00ECÄ
00C4Å
00C59_
144É
00C9æ
00E6Æ
00C6ô
00F4ö
00F6ò
00F2û
00FBù
00F9ÿ
00FFÖ
00D6Ü
00DCø
00F8£
00A3Ø
00D8×
00D7ƒ
0192A_
160á
00E1í
00EDó
00F3ú
00FAñ
00F1Ñ
00D1ª
00AAº
00BA¿
00BF®
00AE¬
00AC½
00BD¼
00BC¡
00A1«
00AB»
00BBB_
176░
2591▒
2592▓
2593│
2502┤
2524Á
00C1Â
00C2À
00C0©
00A9╣
2563║
2551╗
2557╝
255D¢
00A2¥
00A5┐
2510C_
192└
2514┴
2534┬
252C├
251C─
2500┼
253Cã
00E3Ã
00C3╚
255A╔
2554╩
2569╦
2566╠
2560═
2550╬
256C¤
00A4D_
208ð
00F0Ð
00D0Ê
00CAË
00CBÈ
00C8ı
0131Í
00CDÎ
00CEÏ
00CF┘
2518┌
250C█
2588▄
2584¦
00A6Ì
00CC▀
2580E_
224Ó
00D3ß
00DFÔ
00D4Ò
00D2õ
00F5Õ
00D5µ
00B5þ
00FEÞ
00DEÚ
00DAÛ
00DBÙ
00D9ý
00FDÝ
00DD¯
00AF´
00B4F_
240SHY
00AD±
00B1‗
2017¾
00BE¶
00B6§
00A7÷
00F7¸
00B8°
00B0¨
00A8·
00B7¹
00B9³
00B3²
00B2■
25A0NBSP
00A0
Code page 858 _0 _1 _2 _3 _4 _5 _6 _7 _8 _9 _A _B _C _D _E _F 8_
128Ç
00C7ü
00FCé
00E9â
00E2ä
00E4à
00E0å
00E5ç
00E7ê
00EAë
00EBè
00E8ï
00EFî
00EEì
00ECÄ
00C4Å
00C59_
144É
00C9æ
00E6Æ
00C6ô
00F4ö
00F6ò
00F2û
00FBù
00F9ÿ
00FFÖ
00D6Ü
00DCø
00F8£
00A3Ø
00D8×
00D7ƒ
0192A_
160á
00E1í
00EDó
00F3ú
00FAñ
00F1Ñ
00D1ª
00AAº
00BA¿
00BF®
00AE¬
00AC½
00BD¼
00BC¡
00A1«
00AB»
00BBB_
176░
2591▒
2592▓
2593│
2502┤
2524Á
00C1Â
00C2À
00C0©
00A9╣
2563║
2551╗
2557╝
255D¢
00A2¥
00A5┐
2510C_
192└
2514┴
2534┬
252C├
251C─
2500┼
253Cã
00E3Ã
00C3╚
255A╔
2554╩
2569╦
2566╠
2560═
2550╬
256C¤
00A4D_
208ð
00F0Ð
00D0Ê
00CAË
00CBÈ
00C8€
20ACÍ
00CDÎ
00CEÏ
00CF┘
2518┌
250C█
2588▄
2584¦
00A6Ì
00CC▀
2580E_
224Ó
00D3ß
00DFÔ
00D4Ò
00D2õ
00F5Õ
00D5µ
00B5þ
00FEÞ
00DEÚ
00DAÛ
00DBÙ
00D9ý
00FDÝ
00DD¯
00AF´
00B4F_
240SHY
00AD±
00B1‗
2017¾
00BE¶
00B6§
00A7÷
00F7¸
00B8°
00B0¨
00A8·
00B7¹
00B9³
00B3²
00B2■
25A0NBSP
00A0
So the problem likely is sending the Ë in codepage 850/858 encoding with codepoint 0xD3, where the receiving system thinks it is ISO 8859-1 or ISO 8859-15 interpreting codepoint 0xD3 as Ó:
- [Archive.is] Jeroen Wiert Pluimers on Twitter: “Having gained more energy after all cancer treatments, I think I figured out the communication problem between @MediReva and @PostNL mangling accented characters. Can either of these two parties (preferably both) contact me about this? 1/ CC @joerghoh, @isotopp, @LarsFosdal… “
- [Archive.is] Jeroen Wiert Pluimers on Twitter: “The problem likely is sending the Ë in codepage 850/858 encoding with codepoint 0xD3, where the receiving system thinks it is ISO 8859-1 or ISO 8859-15 interpreting codepoint 0xD3 as Ó. 2/2”
xs4all
As a side note: I never got response to [NL] encoding blijft moeilijk, waarom toch? (dit keer in een brief van @xs4all) either, but also did not have the opportunity to re-test that myself.
I tied figuring out if I could find the cause, but these are so distinct, I have not yet found it.
There is still a plan to switch my fibre and VoIP ISP from [Archive.is] @xs4all to [Archive.is] @FreedomNetNL, so maybe one day…
Late 1960s: the first diacritic in a Dutch street name
Back in the late 1960s, Tilburg wanted to name a street after the composer Georg Friedrich Händel (yup, the English Wikipedia page incorrectly rewrote it as George Frideric Handel).
This was the era where (then still 7-bit!) EBCDIC ruled, Unicode was not even in it’s infancy, and ASCII only became a standard in 1969 – the year I was born.
Luckily, already back-then the German language already had digraph replacement (because of the origins of the German umlaut) like ä → ae, ö → oe, ü → ue, so Handel became Haendel, and in 1969 the street was named Haendellaan as Tilburg was afraid “the Computer” (note singular!) would not cope with diacritics well.
With the advent of the Dutch postal code system in 1977, yes in addition to a phone book, in 1978 everybody got a “postcodeboek” as well, it ended up with just one postal code: [Wayback] Postcode Haendellaan in Tilburg – Postcode bij adres.
- [Archive.is] straatnamen on Twitter: “Dat is natuurlijk een – makkelijk te voorkomen – fout van hun website en niet van jouw straatnaam. (Terzijde: toen de gemeente Tilburg in 1969 een straat naar Händel wilde noemen, was men bang dat ‘de computer’ geen raad zou weten met die ä en maakte men er Haendellaan van.)… “
- [Archive.is] Jeroen Wiert Pluimers on Twitter: “1969, toen EBCDIC nog overheersend was, ASCII net geboren en ik op de wereld kwam. … “
- [Wayback] How it was: ASCII, EBCDIC, ISO, and Unicode – EDN
There’s an old engineering joke that says: “Standards are great … everyone should have one!” The problem is that – very often – everyone does.
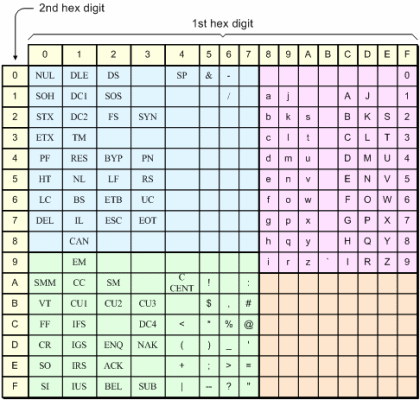
EBCDIC character codes.

- [Wayback] How it was: ASCII, EBCDIC, ISO, and Unicode – EDN
Buildings and address registration in The Netherlands: BAG
The BAG public register (Basisregistratie Adressen en Gebouwen – Wikipedia) has current information on all addresses and buildings.
- FAQ: [Wayback] Basisregistraties Adressen en Gebouwen – PDF Gratis download [Wayback] 17470107.pdf
- Small extract about legal code points in street names: [Wayback] Welke lettertekens mogen in de BAG gebruikt worden voor woonplaatsnamen en straatnamen? | test
–jeroen


Leave a comment