



Scaling, automatically and manually – The Isoblog.
Posted by jpluimers on 2019/01/31
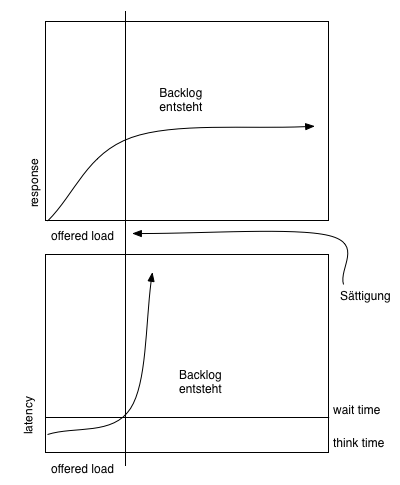 You don’t want to reach the saturation line (Sättigung) on the right: if you do, things go down very fast.
You don’t want to reach the saturation line (Sättigung) on the right: if you do, things go down very fast.
TL;DR of TL;DR:
Reactive autoscaling sucks. Get out of it. Model your shit.
TL;DR:
A reactive scheme where you try automatically detect where the hockey sticks curve mens you are always too late as user experience is already down the drain: no matter the environment, the curve is always too steep to go unnoticed.
If you use loadav in your reactive scheme, you’re lost even more.
So you need a proactive scheme with models. Those models of course are based on prior monitoring of situations where things went bad combined with knowledge on how the system is likely to scale. Each time the system goes bad, refine your models.
Monitoring
I was really glad that Kristian followed up with [WayBack] Monitoring – the data you have and the data you want – The Isoblog.
According to Kristian, the first monitoring tier should be something like [WayBack] Prometheus – Monitoring system & time series database: An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
I’m glad he mentioned that, as I’m a bit fed up with sites having Nagios and Zabbix. Way too cumbersome to setup, and either not far enough features, or the dashboards aren’t insightful enough.
–jeroen
Sources:
- [WayBack] Scaling, automatically and manually – The Isoblog. via [WayBack] Something about scaling, after a conversation with +Tobias Klausmann on that Brendan Gregg article. – Kristian Köhntopp – Google+
- [WayBack] Monitoring – the data you have and the data you want – The Isoblog. via [WayBack] Kristian Köhntopp – Google+ Monitoring – the data you have and the data you want.
Percentile video:


Leave a comment