Archive for the ‘UTF8’ Category
Posted by jpluimers on 2026/06/30
A long time ago (likely around 2009) I remember writing some code to re-encode text files in both Delphi and C#.
Somehow I thought I had published both, but I could only find parts of the C# code back in .NET/C# – converting UTF8 to ASCII (yes, you can loose information with this) using System.Text.Encoding.
So here are some links just in case I ever want to reproduce it in Delphi too (and a reminder to always perform this using TStream derivatives, never use TStrings or derivatives like TStringList for this):
Read the rest of this entry »
Posted in .NET, Ansi, ASCII, C#, Delphi, Development, Encoding, Mojibake, Software Development, UCS-2, UTF-16, UTF-32, UTF-8, UTF16, UTF32, UTF8, Windows-1252 | Leave a Comment »
Posted by jpluimers on 2024/08/22
A while ago, I found the “creëer” mojibake in a Dutch page on the IKEA site.
They were not alone to make this mistake which is easily explained using [Wayback/Archive] ftfy:
>>> ftfy.fix_and_explain("creëer")
ExplainedText(text='creëer', explanation=[('encode', 'latin-1'), ('decode', 'utf-8')])
(you can run this on-line at [Wayback/Archive] Welcome to Python.org: interactive shell, see my post The things I didn’t notice during cancer survival: ftfy 6.0 and more versions got released during my recovery on how to do this)
So the text is easily fixed:
Read the rest of this entry »
Posted in Development, Encoding, ftfy, ISO-8859, ISO8859, Software Development, Unicode, UTF-8, UTF8, Web Development | Leave a Comment »
Posted by jpluimers on 2022/11/22
I have been into more and more Mojibake example pages like [Wayback] Mojibake: Question Marks, Strange Characters and Other Issues | GPI
Have you ever found strange characters like these ��� when viewing content in applications or websites in other languages?
They made me realise that all these (including the Mojibake examples on my blog) are just artifacts, but the real list of examples is the set of ftfy test cases at [Wayback/Archive.is] python-ftfy/test_cases.json at master · LuminosoInsight/python-ftfy
I got reminded when Waternet moved from paper mail using “Pyreneeën” to email using “Pyreneeën“. Not as bad as Waterschap AGV did earlier: they took it one level further and made “Pyreneeën” out of it, see Last year, a classic Mojibake was introduced when Waterschap Amstel, Gooi en Vecht redesigned their IT systems.
This seems like a trend where newer systems perform worse than older systems. I wonder why that is.
BTW: the trick on the [Wayback/Archive] Python.org shell to run ftfy (which is not installed by default) is first dropping to the shell (see my post How do I drop a bash shell from within Python? – Stack Overflow), then starting python again:
Read the rest of this entry »
Posted in CP850, Development, Encoding, ftfy, ISO-8859, Mojibake, Python, Scripting, Software Development, Unicode, UTF-8, UTF8 | Leave a Comment »
Posted by jpluimers on 2022/03/16
Last year, Waterschap Amstel, Gooi en Vecht sent me a paper letter notifying the yearly water bill was going to be late as they were redesigning their IT systems.
Their letter introduced a classic Mojibake that had not been present in all their older paper letter communication.
- Street name on a letter via the old IT systems is
"Pyreneeën":

- Street name on a letter via the new IT systems is
"Pyreneeën":

Read the rest of this entry »
Posted in Development, Encoding, ftfy, Mojibake, Python, Software Development, Unicode, UTF-8, UTF8 | Leave a Comment »
Posted by jpluimers on 2022/02/09
Note: notepad cannot correctly guess the encoding, see the “old new thing”: [Wayback] Some files come up strange in Notepad | The Old New Thing (talking about ANSI a.k.a. Windows-1252, UTF-16LE, UTF-16BE, UTF-8, UTF-7 somewith and some without BOM as Notepad does not understand all permutations)
David Cumps discovered that certain text files come up strange in Notepad. The reason is that Notepad has to edit files in a variety of encodings, and when its back against the wall, sometimes it’s forced to guess.
[Wayback] C# Effective way to find any file’s Encoding – Stack Overflow shows how to detect various byte order marks in C#.
–jeroen
Posted in ASCII, Development, Encoding, Software Development, Unicode, UTF-16, UTF-32, UTF-8, UTF16, UTF32, UTF8 | Leave a Comment »
Posted by jpluimers on 2022/02/08
As a precursor to a post tomorrow showing that serving UTF8 does not mean organisations go without unicode problems, first some statistics.
The first Unicode ideas got drafted some 30 years ago in 1987. In 1991, more than 30 years ago, the Unicode Consortium saw the light. Nowadays more than 95% percent of the web-pages (close to 100% when you include plain ASCII) is served using the UTF-8 encoding.
It means that nowadays there is a very small chance you
will see mangled characters (what Japanese call mojibake) when you’re surfing the web.
Some nice graphs of unicode growth are at these locations are at these locations:
I think especially important are 2008 (when UTF-8 had outgrown all other individual encodings) and slightly after 2010, when UTF-8 alone covered more than 50% of the pages served. These exclude ASCII-only pages. Adding those would make the figures even larger.
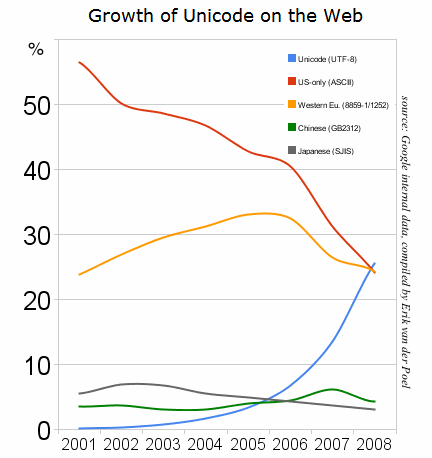



Historical yearly trends in the usage statistics of character encodings for websites, June 2021
–jeroen
Posted in Development, Encoding, Software Development, UTF-8, UTF8, Web Development | Leave a Comment »
Posted by jpluimers on 2022/01/06
Contrary to what many believe is that MySQL utf8 is not always full blown UTF-8 support, but actually utf8mb3, which has been deprecated for a while now.
Only utf8mb4 will give you full blown UTF-8 support.
This when someone reminded me of this in a Delphi application:
When I insert :joy: emoji into mysql varchar filed I got an error :
#22007 Incorrect string value: '\xF0\x9F\x98\x82' for column 'remarks' at row 1
database charset is utf8
Note that the :joy: emoji is 😂 and has Unicode code point U+1F602 which is outside the basic multilingual plane.
See:
- [Wayback] Unicode Character ‘FACE WITH TEARS OF JOY’ (U+1F602)
- Plane (Unicode): Overview, Basic Multilingual Plane – Wikipedia
- [Archive.is] Kristian Köhntopp on Twitter: “MySQL also, for quite some time now, no longer updates its own charsets and collations internally, for the same reason. So utf8 in MySQL is utf8mb3, the three byte variant of Unicode UTF-8 implementation that covers only the BMP (unicode up to U+FFFF).”
- Kristian Köhntopp
»Where does PostgreSQL’s collation logic come from?
PostgreSQL relies on external libraries to order strings.
– libc, meaning the operating system locale facility (POSIX or Windows)
– icu, meaning the ICU project (if PostgreSQL was built with ICU support)«
- MySQL does things differently:
MySQL binary data files are independent of the host operating system in byte order, number representation (as long as the host fulfils MySQLs basic requirements), collation and even time zone handling.
- So MySQL implements collations internally, also to guarantee stability across OS updates.
If it didn’t, a libc update changing collations would mean you have to recreate a lot of indexes. Also, you would not be able to safely move data files from host to host.
- MySQL also, for quite some time now, no longer updates its own charsets and collations internally, for the same reason.
So utf8 in MySQL is utf8mb3, the three byte variant of Unicode UTF-8 implementation that covers only the BMP (unicode up to U+FFFF).
- When moving to fuller (multiplane) UTF-8 support, a new name was needed, and utf8mb4 was chosen.
So when you actually want modern utf8 in MySQL, you have to use utf8mb4, and now you know why.
- utf8 is deprecated and will be upgraded to utf8mb4 in some future MySQL release. This will be a breaking upgrade, and I wonder if it will require dropping and recreating all indexes affected by the change.
That will be painful.
- https://dev.mysql.com/doc/refman/8.0/en/charset-unicode-utf8mb3.html …
utf8mb3 page in the MySQL 8.0 manual, with deprecation notice.
What will change is the meaning of the alias utf8 (currently an alias for utf8mb3).
- [Wayback] MySQL: Some Character Set Basics | Die wunderbare Welt von Isotopp
- [Wayback] MySQL :: MySQL 8.0 Reference Manual :: 10.9.2 The
utf8mb3 Character Set (3-Byte UTF-8 Unicode Encoding)
utf8 is an alias for utf8mb3; the character limit is implicit, rather than explicit in the name.
Note
The utf8mb3 character set is deprecated and you should expect it to be removed in a future MySQL release. Please use utf8mb4 instead. Although utf8 is currently an alias for utf8mb3, at some point utf8 is expected to become a reference to utf8mb4. To avoid ambiguity about the meaning of utf8, consider specifying utf8mb4 explicitly for character set references instead of utf8.
- [Wayback] MySQL :: MySQL 8.0 Reference Manual :: 10.9.1 The utf8mb4 Character Set (4-Byte UTF-8 Unicode Encoding)
utf8mb4 contrasts with the utf8mb3 character set, which supports only BMP characters and uses a maximum of three bytes per character:
- For a BMP character,
utf8mb4 and utf8mb3 have identical storage characteristics: same code values, same encoding, same length.
- For a supplementary character,
utf8mb4 requires four bytes to store it, whereas utf8mb3 cannot store the character at all. When converting utf8mb3 columns to utf8mb4, you need not worry about converting supplementary characters because there are none.
–jeroen
Posted in Conference Topics, Conferences, Database Development, Delphi, Development, Encoding, Event, MySQL, Software Development, UTF-8, UTF8 | Leave a Comment »
Posted by jpluimers on 2021/09/29
The below one will fail in a script, both both work from the PowerShell prompt:
Success
Get-NetFirewallRule -DisplayGroup "File and Printer Sharing" | ForEach-Object { Write-Host $_.DisplayName ; Get-NetFirewallAddressFilter -AssociatedNetFirewallRule $_ }
Failure
Get-NetFirewallRule –DisplayGroup "File and Printer Sharing" | ForEach-Object { Write-Host $_.DisplayName ; Get-NetFirewallAddressFilter -AssociatedNetFirewallRule $_ }
The error you get this this:
At C:\bin\Show-File-and-Printer-Sharing-firewall-rules.ps1:5 char:52
+ ... -TCP-NoScope" | ForEach-Object { Write-Host $_.DisplayName ; Get-NetF ...
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The string is missing the terminator: ".
+ CategoryInfo : ParserError: (:) [], ParentContainsErrorRecordException
+ FullyQualifiedErrorId : TerminatorExpectedAtEndOfString
Via [WayBack] script file ‘The string is missing the terminator: “.’ – Google Search, I quickly found these that stood out:
Cause and solution
Before DisplayGroup, the first line has a minus sign and the second an en-dash. You can see this via [WayBack] What Unicode character is this ?.
Apparently, when using Unicode on the console, it does not matter if you have a minus sign (-), en-dash (–), em-dash (—) or horizontal bar (―) as dash character. You can see this in [WayBack] tokenizer.cs at function [WayBack] NextToken and [WayBack] CharTraits.cs at function [WayBack] IsChar).
When saving to a non-Unicode file, it does matter, even though it does not display as garbage in the error message.
Similarly, PowerShell has support for these special characters:
internal static class SpecialChars
{
// Uncommon whitespace
internal const char NoBreakSpace = (char)0x00a0;
internal const char NextLine = (char)0x0085;
// Special dashes
internal const char EnDash = (char)0x2013;
internal const char EmDash = (char)0x2014;
internal const char HorizontalBar = (char)0x2015;
// Special quotes
internal const char QuoteSingleLeft = (char)0x2018; // left single quotation mark
internal const char QuoteSingleRight = (char)0x2019; // right single quotation mark
internal const char QuoteSingleBase = (char)0x201a; // single low-9 quotation mark
internal const char QuoteReversed = (char)0x201b; // single high-reversed-9 quotation mark
internal const char QuoteDoubleLeft = (char)0x201c; // left double quotation mark
internal const char QuoteDoubleRight = (char)0x201d; // right double quotation mark
internal const char QuoteLowDoubleLeft = (char)0x201E; // low double left quote used in german.
}
The easiest solution is to use minus signs everywhere.
Another solution is to save files as Unicode UTF-8 encoding (preferred) or UTF-16 encoding (which I dislike).
–jeroen
Posted in .NET, CommandLine, Development, Encoding, PowerShell, PowerShell, Scripting, Software Development, Unicode, UTF-16, UTF-8, UTF16, UTF8 | Leave a Comment »
Posted by jpluimers on 2021/01/21
I should have had the below answer when writing about StUF – receiving data from a provider where UTF-8 is in fact ISO-8859.
A while ago, a co-worker did not believe when I told that default XML encoding really is UTF-8 (and tried to force it to utf-8), and that if the content had byte sequences different from the (either specified or default) encoding, it was a problem.
I though I blogged about the default, and where to find it, but apparently, I did not.
My blog had (and has <g>) a truckload of articles mentioning UTF-8, less articles containing UTF-8, encoding and xml, but the ones having UTF-8, default, encoding and xml did not actually tell about a standard that really defines XML uses UTF-8 as default encoding when there is no other encoding information – like BOM (byte order mark), HTTP, or MIME encoding) available.
W3C indeed specifies it. [WayBack] utf 8 – How default is the default encoding (UTF-8) in the XML Declaration? – Stack Overflow has a summary (thanks James Holderness!):
The Short Answer
Under the very specific circumstances of a UTF-8 encoded document with no external encoding information (which I understand from the comments is what you’re interested in), there is no difference between the two declarations.
The long answer is far more interesting though.
and an elaboration:
Read the rest of this entry »
Posted in Development, Encoding, Software Development, UTF-8, UTF8, XML, XML/XSD | Leave a Comment »
Posted by jpluimers on 2020/03/11
Bad surprise of the day: SysUtils.TEncoding in XE2+ defaults to ANSI, while in XE it defaulted to UTF-8 .Among other things this means that TStringList… – Eric Grange – Google+
Source: Bad surprise of the day: SysUtils.TEncoding in XE2+ defaults to ANSI, while i…
Delphi

+Stefan Glienke Indeed, you’re right. The issue must be deeper somewhere. Don’t have time to investigate too much, I’m bypassing the RTL now (also have to work around the limitation that for utf-8 the TEncoding.GetString method returns an empty string if one character in the buffer isn’t utf-8)

I wouldn’t trust the RTL at all with loading non-ascii text, we’ve had it hang on invalid UTF-8 codes more than once.
–jeroen
Posted in Ansi, Delphi, Development, Encoding, Software Development, UTF-8, UTF8 | Leave a Comment »








