



Last year, a classic Mojibake was introduced when Waterschap Amstel, Gooi en Vecht redesigned their IT systems
Posted by jpluimers on 2022/03/16
Last year, Waterschap Amstel, Gooi en Vecht sent me a paper letter notifying the yearly water bill was going to be late as they were redesigning their IT systems.
Their letter introduced a classic Mojibake that had not been present in all their older paper letter communication.
- Street name on a letter via the old IT systems is
"Pyreneeën":

- Street name on a letter via the new IT systems is
"Pyreneeën":

It’s easily fixed by [Wayback/Archive.is] ftfy · PyPI:
Python 3.9.5 (default, May 27 2021, 19:45:35) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import ftfy >>> ftfy.fix_text("Pyreneeën") 'Pyreneeën' >>>
Below is the English translation of the Dutch Twitter thread below the signature.
Reminder to self to check if this got fixed after I notified their web-care via
[Archive.is] Jeroen Wiert Pluimers on Twitter: “Ik heb in 2019 al eens over de oorzaak een blog-post geschreven: een UTF-8 encoding van een karakter wordt 1 of meer keer vervormd door de UTF-8 bytes opnieuw als Unicode code-points te beschouwen en daarna nog een keer UTF-8 van te maken. 2/”
[Wayback/Archive.is] Thread by @jpluimers on Thread Reader App – Thread Reader App
Luckily, @WoonVeilig isn’t alone. @waterschapagv is redesigning their IT systems. It means addresses are now handled wrongly in their paper correspondence: non-ASCII characters are mangled (techno-speak: #Mojibake)
Just look at the scans from letters in 2020 and 2021:
Back in 2019, I wrote a blog post highlighting the cause of an almost identical failure: the UTF-8 encoding of a character gets malformed one or more times by re-treating the UTF-8 bytes Unicode code-points one or more times and then each round emitting them as UTF-8.
This example from the blog post matches: in exactly two rounds of mangling the lowercase letter e-diaeresis
ëbecomes a series of four characters:ë.Hopefully I’ve given up on entering non-ASCII characters when entering data on-line helps @waterschapagv fixing this issue.

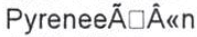
Involved unicode original characters (thanks to [Wayback] What Unicode character is this ?):
- [Wayback] Unicode Character ‘LATIN SMALL LETTER E WITH DIAERESIS’ (U+00EB) , which is
0xC3 0xABin UTF-8 - [Wayback] Unicode Character ‘LATIN CAPITAL LETTER A WITH TILDE’ (U+00C3)
- [Wayback] Unicode Character ‘NO BREAK HERE’ (U+0083)
- [Wayback] Unicode Character ‘LATIN CAPITAL LETTER A WITH CIRCUMFLEX’ (U+00C2)
- [Wayback] Unicode Character ‘LEFT-POINTING DOUBLE ANGLE QUOTATION MARK’ (U+00AB) {left guillemet; chevrons (in typography)}
This might actually be related to [Archive.is] Waternet int ineens 7 maanden aan drinkwaterkosten: ‘Echt belachelijk’ | Het Parool.
–jeroen


Leave a comment