Archive for the ‘internatiolanization (i18n) and localization (l10)’ Category
Posted by jpluimers on 2023/11/14
Apparently you have to do this once for a Google account, as it is on the account level, not the web-browser level.
The odd thing was that somehow despite setting the country to The Netherlands when setting up the account, these were the settings in Google Calendar
- Language: English (UK)
- Country: Netherlands (Nederland)
- Date format: 12/31/2021
- Time format: 1:00pm
After the steps from [Wayback] How to Switch to a 24 Hour Clock in Google Calendar – Live2Tech, the settings now are these:
Read the rest of this entry »
Posted in Development, Google, GoogleCalendar, internatiolanization (i18n) and localization (l10), Power User | Leave a Comment »
Posted by jpluimers on 2021/08/04
Not all letters have superscript or subscript counterparts. The counterparts are from different ranges, so might not look nice when next to each other.
I think 20th using Unicode lowercase superscript looks ugly 20ᵗʰ. With uppercase superscript it is somewhat OK: 20ᵀᴴ.
The list is from [WayBack] javascript – How to find the unicode of the subscript alphabet? – Stack Overflow:
Take a look at the wikipedia article Unicode subscripts and superscripts. It looks like these are spread out across different ranges, and not all characters are available.
Consolidated for cut-and-pasting purposes, the Unicode standard defines complete sub- and super-scripts for numbers and common mathematical symbols ( ⁰ ¹ ² ³ ⁴ ⁵ ⁶ ⁷ ⁸ ⁹ ⁺ ⁻ ⁼ ⁽ ⁾ ₀ ₁ ₂ ₃ ₄ ₅ ₆ ₇ ₈ ₉ ₊ ₋ ₌ ₍ ₎ ), a full superscript Latin lowercase alphabet except q ( ᵃ ᵇ ᶜ ᵈ ᵉ ᶠ ᵍ ʰ ⁱ ʲ ᵏ ˡ ᵐ ⁿ ᵒ ᵖ ʳ ˢ ᵗ ᵘ ᵛ ʷ ˣ ʸ ᶻ ), a limited uppercase Latin alphabet ( ᴬ ᴮ ᴰ ᴱ ᴳ ᴴ ᴵ ᴶ ᴷ ᴸ ᴹ ᴺ ᴼ ᴾ ᴿ ᵀ ᵁ ⱽ ᵂ ), a few subscripted lowercase letters ( ₐ ₑ ₕ ᵢ ⱼ ₖ ₗ ₘ ₙ ₒ ₚ ᵣ ₛ ₜ ᵤ ᵥ ₓ ), and some Greek letters ( ᵅ ᵝ ᵞ ᵟ ᵋ ᶿ ᶥ ᶲ ᵠ ᵡ ᵦ ᵧ ᵨ ᵩ ᵪ ). Note that since these glyphs come from different ranges, they may not be of the same size and position, depending on the typeface.
After a nice chat with my nephew EWD, I did some research and found the above via
–jeroen
Posted in Development, Encoding, internatiolanization (i18n) and localization (l10), Power User, Software Development, Unicode | Leave a Comment »
Posted by jpluimers on 2021/06/29
A few statements go get database names and IDs based on these functions or system tables:
Part of it has the assumption that a master database always exists.
-- gets current database name
select db_name() as name
;
name
--------------------------------------------------------------------------------------------------------------------------------
acc
(1 row affected)
-- gets current database ID
select db_id() as dbid
;
dbid
------
5
(1 row affected)
-- gets all database IDs and names
select dbid,name from sys.sysdatabases
;
dbid name
------ --------------------------------------------------------------------------------------------------------------------------------
1 master
5 acc
(2 rows affected)
-- gets current database name by ID
select db_name(db_id()) as name
;
name
--------------------------------------------------------------------------------------------------------------------------------
acc
(1 row affected)
-- gets case corrected database name for sys.sysdatabases.name having a case insensitive collation sequence
select dbid,name from sys.sysdatabases
where name='Master'
;
dbid name
------ --------------------------------------------------------------------------------------------------------------------------------
1 master
(1 row affected)
-- gets case corrected database name for sys.sysdatabases.name having a case sensitive collation sequence
select dbid,name from sys.sysdatabases
where name = 'Master' collate Latin1_General_100_CI_AI
;
dbid name
------ --------------------------------------------------------------------------------------------------------------------------------
1 master
(1 row affected)
Note that:
- even though by default the SQL server collation sequence is case insensitive, it can make sense to do a case insensitive search, for example by using the
upper function, specifying a collation, or casting to binary. I like upper the most, because – though less efficient – it is a more neutral SQL idiom.
- the most neutral case insensitive collation seems to be
Latin1_General_100_CI_AI
Related:
- [WayBack] SQL server ignore case in a where expression – Stack Overflow answered by Solomon Rutzky, summarised as:
- Do not use
upper as upper with lower does not always round-trip.
- Do not use
varbinary as it is not case insensitive.
- Neither the
= or like operators are case sensitive by default: both need a collate clause.
- Find the collation of the column(s) involved; if it contains
_CI, then you are done (it is already case insensitive); if it contains _CS, then replace that with _CI (case insensitive) and add that in a collate clause.
- Collations are per
predicate, so not per query, per table, per column nor per database. This means you have to specify them if you want to use a different one than the default.
- [WayBack] What is Collation in Databases? | Database.Guide
Latin1_General_100_CI_AI |
Latin1-General-100, case-insensitive, accent-insensitive, kanatype-insensitive, width-insensitive |
- [WayBack] Collation Info: Information about Collations and Encodings for SQL Server
- [WayBack] SQL Instance Collation – Language Neutral Required:
I recommend using Latin1_General_100_CI_AI. I recommend this because:
…
- If
Latin1_General_CI_AI is supported, then there’s almost no chance thatLatin1_General_100_CI_AI (which is a far better choice) isn’t also supported. The version 100 collation has about 15,400 more sort weight definitions, plus 438 more uppercase/lowercase mappings. Not having those sort weights means that 15,400 more characters in the non-100 version equate to space, an empty string, and to each other. Not having those case mappings means that 438 more characters in the non-100 version return the character passed in (i.e. no change) for the UPPER() and LOWER() functions. There is no reason at all to want Latin1_General_CI_AI instead of Latin1_General_100_CI_AI. There might be a need if code was put into place to work around these deficiencies, and that code would behave incorrectly under the newer, better version of that collation. However, it’s highly unlikely that code was put into place to account for this, and extremely unlikely that if such code did exist, that it would error or doing things incorrectly due to the newer collation.
- [WayBack] Differences Between the Various Binary Collations (Cultures, Versions, and BIN vs BIN2) – Sql Quantum Leap
- [WayBack] How to do a case sensitive search in WHERE clause (I’m using SQL Server)? – Stack Overflow answered by Jonas Lincoln:
By using collation or casting to binary, like this:
SELECT *
FROM Users
WHERE
Username = @Username COLLATE SQL_Latin1_General_CP1_CS_AS
AND Password = @Password COLLATE SQL_Latin1_General_CP1_CS_AS
AND Username = @Username
AND Password = @Password
The duplication of username/password exists to give the engine the possibility of using indexes. The collation above is a Case Sensitive collation, change to the one you need if necessary.
The second, casting to binary, could be done like this:
SELECT *
FROM Users
WHERE
CAST(Username as varbinary(100)) = CAST(@Username as varbinary))
AND CAST(Password as varbinary(100)) = CAST(@Password as varbinary(100))
AND Username = @Username
AND Password = @Password
- [WayBack] sql – How to get Database name of sqlserver – Stack Overflow
–jeroen
Posted in Database Development, Development, Encoding, internatiolanization (i18n) and localization (l10), SQL Server | Leave a Comment »
Posted by jpluimers on 2020/01/27
I wrote about Delphi, IBX and the Turkish I problem about a year and a half ago. Back then, I could use a US-English system to reproduce the problem. This time, I had a problem on a Turkish system running an embedded version of Windows with hardly any UI tools available (especially no Windows Explorer).
 Luckily, I had the command prompt, but it looked like this:
Luckily, I had the command prompt, but it looked like this:
X:\>mode con codepage
Status for device CON:
----------------------
Code page: 857
X:\>mode con codepage select 437
Invalid parameter - select
X:\>mode con codepage select=437
Invalid parameter - select
Status for device CON:
----------------------
Lines: 300
Columns: 120
Keyboard rate: 31
Keyboard delay: 1
Code page: 437
X:\>
I tried the [WayBack] modecommand to change from [WayBack] code page 857(Turkish) to [WayBack] code page 437(IBM PC or OEM-US) which is the default on US-English systems, but that did not change the keyboard locale, not even for the command prompt.
Read the rest of this entry »
Posted in Development, internatiolanization (i18n) and localization (l10), Power User, Software Development | Leave a Comment »
Posted by jpluimers on 2019/09/13
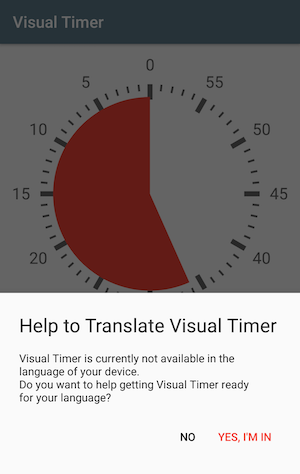 Interesting approach on how a free app got itself free translations: Case Study on engaging users to become app translators
Interesting approach on how a free app got itself free translations: Case Study on engaging users to become app translators
Source: [WayBack] Crowdsourcing App-Translation with in-app message – Christoph Wiesner – Medium
The app: Visual Timer – Countdown
Platforms used:
- Firebase is Google’s mobile platform that helps you quickly develop high-quality apps and grow your business.Source: Firebase
- POEditor is an online localization management tool, perfect for collaborative or crowdsourced translation projects. Translate websites, apps, games and more!Source: Software Localization Management Platform
Via:
–jeroen
Posted in Android Devices, Development, internatiolanization (i18n) and localization (l10), Power User, Software Development | Leave a Comment »
Posted by jpluimers on 2018/10/23
A very interesting thread at [WayBack] Do i need to create one TFormatSettings instance for each thread that needs it? If i want the same settings (for all threads), th… – Dany Marmur – Google+
It’s about:
Recommended reading!
It made me go back to these style guides (from oldest to newest):
And Stefan Glienke reminded me naming is always hard, so I found back these from a distant past:
Note most of the above Links point to (archives of) Delphi 2007 documentation as the behaviour is that old and that the below identifiers were not mentioned in the thread.
The FormatSettings variable was introduced in Delphi XE but only documented in XE2 and up.
Until that, other global variables like the [WayBack] SysUtils.DecimalSeparator Variable were used.
–jeroen
Read the rest of this entry »
Posted in Delphi, Development, internatiolanization (i18n) and localization (l10), Software Development | Leave a Comment »
Posted by jpluimers on 2018/06/05
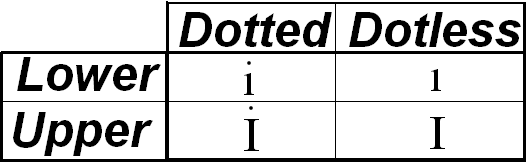
 Reminder to self: in Turkey, they have more than just the lowercase i and uppercase I. In fact these are the i characters you can get:
Reminder to self: in Turkey, they have more than just the lowercase i and uppercase I. In fact these are the i characters you can get:
Note there are more non-US latin characters in Turkey, see the links below for some lists.
The Turkish case conversion is inside the same group of dotted. The English case conversion is from dotted lowercase i to dotless uppercase I as shown in [WayBack] Internationalizing Turkish: Dotted and Dotless Turkish Letter “I”:
English vs. Turkish Case Mappings
| Language |
Letter |
Lowercase
Map |
Uppercase
Map |
| English |
i |
i |
I |
| Turkish |
dotted i |
i |
İ |
| Turkish |
dotless ı |
ı |
I |
In general, this problem is called [WayBack] Case Folding and many environments do not have good and ready to use solutions for this.
In my case, I was getting Field "id" not found messages for all tables that had an ID field. The reason was that somewhere in the path from my code to the database, either a comparison or case conversion wasn’t taking into account the above mappings.
Though the underlying database indicates I shouldn’t in [WayBack] Do I have to use UPPERCASE identifiers?, it appears that something in the path from my code via IBX to the Firebird 2.5 database has issues on Turkish machines. The good thing: Database WorkBench 5.x doesn’t have that issue for a regular query.
Usually databases are only cases sensitive with quoted identifiers, but not all are: [WayBack] Lorenzo Alberton – Articles – Database identifiers, quoting and case sensitivity
Read the rest of this entry »
Posted in Development, internatiolanization (i18n) and localization (l10), Software Development | Leave a Comment »
Posted by jpluimers on 2018/05/14
Since:
- many people use the left-alt key as it as it is more accessible
- development tools uses a lot of Alt-Shift based keyboard shortcuts
- Windows by default has the Left Alt+Shift shortcut enabled to switch language+keyboard layout combinations
- In most countries, Windows by default has more than one language+keyboard combination installed
- Windows remembers per application instance which language+keyboard combination is used
every now and then you will get strange characters in only your development tools.
You can change this Windows setting, but be aware that every now and then, various Windows versions will re-enable the Left Alt+Shift even if you have previously disabled it. As of Windows 7 this occurs far less often, but still seems to occur.
Source: Question: Does anyone else have instances in the IDE (Berlin but has happened…
Comments at https://plus.google.com/+JeroenPluimers/posts/ektRa2qW92L
Posted in internatiolanization (i18n) and localization (l10), Keyboards and Keyboard Shortcuts, Power User, Windows | Leave a Comment »
Posted by jpluimers on 2018/01/02
I totally missed the passing of Michael Scott Kaplan some 2 years ago, so a belated R.I.P. is in place.
Obituary for Michael Kaplan, Michael Scott Kaplan, 45, passed away Wednesday, October 21, 2015, in Redmond, WA, after a brave battle with MS for 25 years. He was a lead software developer for Microsoft.
Source: [WayBack] Michael Kaplan Obituary – Berkowitz-Kumin-Bookatz | Cleveland Heights OH
Michael was the leading source on i18n, L10N, Unicode, sorting, normalisation and other things having to do with languages, representations and writing.
Besides that he was a really nice guy of which I enjoyed his MSDN materials.
Other people enjoy that too, so I’m glad his writings have been archived: [first archive.is, second archive.is, WayBack] Sorting it All Out: Archives
Here are some additional links:
More on miloush.net:
Read the rest of this entry »
Posted in Ansi, Development, Encoding, internatiolanization (i18n) and localization (l10), Software Development, The Old New Thing, UTF-8, UTF8, Windows Development | Leave a Comment »















{kind=link}