- [WayBack] Jimmy Bogard 🍻 on Twitter: “I remember doing all this in like 2005-8 and it worked well when I didn’t have an ORM doing this junk and horribly when it did”
- [WayBack] Matthew Tanner on Twitter: “… ”
–jeroen
Posted by jpluimers on 2021/07/20
–jeroen

Posted in .NET, Design Patterns, Development, Software Development | Leave a Comment »
Posted by jpluimers on 2021/07/15
For my link archive: [WayBack] c# – Algorithm to check whether a certain hour falls into a given time period – Stack Overflow answered by [WayBack] kennytm:
Assume you only have the time and not the date.
if end_time >= start_time: return start_time <= current_time <= end_time else: return start_time <= current_time or current_time <= end_time
I totally agree with this comment:
This is brilliant! Thanks a lot. – Martin Dimitrov [WayBack]
I love it when algorithms are simple and elegant.
It reminded me of another scheduling related algorithm: [WayBack] Activity Selection Problem | Greedy Algo-1 – GeeksforGeeks
–jeroen
Posted in .NET, Algorithms, C#, Development, Software Development | Leave a Comment »
Posted by jpluimers on 2021/07/13
For my link archive:
–jeroen
Posted in .NET, Delphi, Development, Software Development | Leave a Comment »
Posted by jpluimers on 2021/07/07
There are quite a few posts that recommend using SetProcessWorkingSetSize to trim your process working set, usually in the SetProcessWorkingSetSize(ProcessHandle, -1, -1) form:
[WayBack] SetProcessWorkingSetSize function (winbase.h) | Microsoft Docs
Sets the minimum and maximum working set sizes for the specified process.
BOOL SetProcessWorkingSetSize( HANDLE hProcess, SIZE_T dwMinimumWorkingSetSize, SIZE_T dwMaximumWorkingSetSize );The working set of the specified process can be emptied by specifying the value
(SIZE_T)–1for both the minimum and maximum working set sizes. This removes as many pages as possible from the working set. The [WayBack] EmptyWorkingSet function can also be used for this purpose.
In practice you hardly ever have to do this, mainly because this will write – regardless of (dis)usage – all of your memory to the pagefile, even the memory your frequently use.
Windows has way better heuristics to do that automatically for you, skipping pages you frequently use.
It basically makes sense in a few use cases, for instance when you know that most (like 90% or more) of that memory is never going to be used again.
Another use case (with specific memory sizes) is when you know that your program is going to use a defined range of memory, which is outside what Windows will heuristically expect from it.
A few more links that go into more details on this:
SetProcessWorkingSetSize()controls the amount of RAM that your process uses, it doesn’t otherwise have any affect on the virtual memory size of your process. Windows is already quite good at dynamically controlling this, swapping memory pages out on demand when another process needs RAM.By doing this manually, you slow down your program a lot, causing a lot of page faults when Windows is forced to swap the memory pages back in.
SetProcessWorkingSetSizeis typically used to increase the amount of RAM allocated for a process. Or to force a trim when the app knows that it is going to be idle for a long time. Also done automatically by old Windows versions when you minimize the main window of the app.
The only good use case I’ve seen for this call is when you KNOW your process is going to hog a lot of the system’s RAM and you want to reserve it for the duration. You use it to tell the OS “Yes, I’m going to eat a lot of the system RAM during my entire run and don’t get in my way”.
We have found out that, for a GUI application written in Delphi for Win32/Win64 or written in a similar way that uses large and heavy libraries on top of the Win32 API (GDI, etc), it is worth calling
SetProcessWorkingSetSizeonce.We call it with -1, -1 parameters, within a fraction of second after the application has fully opened and showed the main window to the user. In this case, the
SetProcessWorkingSetSize(... -1, -1)releases lots of startup code that seem to not needed any more.
Don’t pinvoke this, just use the
Process.CurrentProcess.MinWorkingSetproperty directly.Very high odds that this won’t make any difference. Soft paging faults are entirely normal and resolved very quickly if the machine has enough RAM. Takes ~0.7 microseconds on my laptop. You can’t avoid them, it is the behavior of a demand_paged virtual memory operating system like Windows. Very cheap, as long as there is a free page readily available.
But if it “blips” you program performance then you need to consider the likelihood that it isn’t readily available and triggered a hard page fault in another process. The paging fault does get expensive if the RAM page must be stolen from another process, its content has to be stored in the paging file and has to be reset back to zero first. That can add up quickly, hundreds of microseconds isn’t unusual.
The basic law of “there is no free lunch”, you need to run less processes or buy more RAM. With the latter option the sane choice, 8 gigabytes sets you back about 75 bucks today. Complete steal.
I had an application which by default would close down entirely but keep listening for certain events. However, most of my code at that point would not be needed for a long time. To reduce the impact my process made, I called
SetProcessWorkingSetSize(-1,-1);. This meant Windows could take back the physical RAM and give it to other apps. I’d get my RAM back when events did arrive.That’s of course unrelated to your situation, and I don’t think you’d benefit.
If your goal is for your application to use less memory you should look elsewhere. Look for leaks, look for heap fragmentations look for optimisations and if you think FastMM is keeping you from doing so you should try to find facts to support it. If your goal is to keep your workinset size small you could try to keep your memory access local. Maybe FastMM or another memory manager could help you with it, but it is a very different problem compared to using to much memory.
…
you can check the FasttMM memory usage via FasttMM calls GetMemoryManagerState and GetMemoryManagerUsageSummary before and after calling API SetProcessWorkingSetSize.
…
I don’t need to use SetProcessWorkingSetSize. FastMM will eventually release the RAM.
To confirm that this behavior is generated by FastMM (as suggested by Barry Kelly) I crated a second program that allocated A LOT of RAM. As soon as Windows ran out of RAM, my program memory utilization returned to its original value.
Yes, it’s a bad thing. You’re telling the OS that you know more about memory management than it does, which probably isn’t true. You’re telling to to page all your inactive memory to disk. It obeys. The moment you touch any of that memory again, the OS has to page it back into RAM. You’re forcing disk I/O that you don’t actually know you need.
If the OS needs more free RAM, it can figure out which memory hasn’t been used lately and page it out. That might be from your program, or it might be from some other program. But if the OS doesn’t need more free RAM, then you’ve just forced a bunch of disk I/O that nobody asked for.
If you have memory that you know you don’t need anymore, free it. Don’t just page it to disk. If you have memory that the OS thinks you don’t need, it will page it for you automatically as the need arises.
Also, it’s usually unwise to call
Application.ProcessMessagesunless you know there are messages that your main thread needs to process that it wouldn’t otherwise process by itself. The application automatically processes messages when there’s nothing else to do, so if you have nothing to do, just let the application run itself.
–jeroen
Posted in .NET, C, C++, Delphi, Development, Software Development, Windows Development | Leave a Comment »
Posted by jpluimers on 2021/06/24
Interesting takeaway from [WayBack] DCOM calls from thread pool threads
call
CoInitialize*at the start, and callCoUninitializebefore returning. Expensive, but necessary
Related:
–jeroen
Posted in .NET, C, C++, COM/DCOM/COM+, Delphi, Development, Software Development, Windows Development | Leave a Comment »
Posted by jpluimers on 2021/06/24
Usually when I see this error [Wayback] “No mapping for the Unicode character exists in the target multi-byte code page” – Google Search, it is in legacy code that uses string buffers where decoding or decompressing data into.
This is almost always wrong no matter what kind of data you use, as it will depend in your string encoding.
I have seen it happen especially in these cases:
Most cases I encountered were in Delphi and C code, but surprisingly I also bumped into C# exhibiting this behaviour.
I’m not alone, just see these examples from the above Google search:
TFile.AppendAllBytes which is still present in Delphi 10.2 Tokyo, and likely newer versions)–jeroen
Posted in .NET, base64, C, C#, C++, Delphi, Development, Encoding, Software Development, Unicode | Leave a Comment »
Posted by jpluimers on 2021/05/27
A few links for my link archive, as I often edit XML files (usually with different extensions than .xml, because historic choices that software development vendors make, which makes it way harder to tell editors “yes, this too is XML).
This plugin is a small set of useful tools for editing XML with Notepad++. The plugin is libXML2-based. The plugin features are:
– XML syntax Check
– XML Schema (XSD) + DTD Validation
– XML tag autoclose
– Pretty print
– Linarize XML
– Current XML Path
– Conversion XML &lt;-&gt; Text
– Comment / Uncomment
– XPath expression evaluation
Author: Nicolas Crittin
Homepage: https://github.com/morbac/xmltools
–jeroen

Posted in .NET, Development, Notepad++, Power User, Software Development, Text Editors, Visual Studio and tools, vscode Visual Studio Code, XML, XML/XSD | Leave a Comment »
Posted by jpluimers on 2021/05/26
Bummer: I tried to inherit the build events from a base configuration, then add some extra steps for some of the inheriting configurations.
Those configurations just executed the extra steps, not the inherited steps.
This affects Visual Studio, Delphi and any other tool based on msbuild, as this is an ms-build thing:
How do I then specify additional project-specific Post-Build Events? The usual “Inherit from parent or project defaults” is missing, and I would rather not have to manually add
barto every single project as it makes it hard to maintain.
–jeroen
Posted in .NET, Continuous Integration, Delphi, Development, msbuild, Software Development, Visual Studio and tools | Leave a Comment »
Posted by jpluimers on 2021/05/18
A while ago, I needed to get RowVersion binary data out of SQL Server. People around me told me it is stored as BigInt.
I luckily bumped into [WayBack] sql server – Cast rowversion to bigint – Stack Overflow.
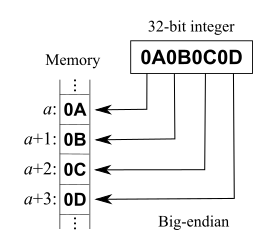
That post explains RowVersion is not stored as BigInt. Both RowVersion and BigInt take up 8 bytes of storage, but RowVersion is big-endian and unsigned, whereas BigInt is little-endian and signed.
A few quotes from it:
In my C# program I don’t want to work with byte array, therefore I cast rowversion data type to bigint:
SELECT CAST([version] AS BIGINT) FROM [dbo].[mytable]So I receive a number instead of byte array. Is this conversion always successful and are there any possible problems with it? If so, in which data type should I cast rowversion instead?
and
You can convert in C# also, but if you want to compare them you should be aware that rowversion is apparently stored big-endian, so you need to do something like:
byte[] timestampByteArray = ... // from datareader/linq2sql etc... var timestampInt = BitConverter.ToInt64(timestampByteArray, 0); timestampInt = IPAddress.NetworkToHostOrder(timestampInt);It’d probably be more correct to convert it as ToUInt64, but then you’d have to write your own endian conversion as there’s no overload on NetworkToHostOrder that takes uint64. Or just borrow one from Jon Skeet (search page for ‘endian’).
Code: [WayBack] Jon Skeet: Miscellaneous Utility Library
Related:
The Intel x86 and also AMD64 / x86-64 series of processors use the little-endian format, and for this reason, it is also known in the industry as the “Intel convention“.
Endianness is also important
Additionally, as Mark pointed out,
BitConverter.GetUInt64is not converting properly. Mark is not completely right–BitConverteris either big-endian or little-endian depending on the system it’s running on.
--jeroen

Posted in .NET, Database Development, Delphi, Development, Jon Skeet, Software Development, SQL Server | Leave a Comment »
Posted by jpluimers on 2021/05/04
On my list to experiment with are [Wayback] about_Preference_Variables – PowerShell | Microsoft Docs, especially
$ConfirmPreference
Determines whether PowerShell automatically prompts you for confirmation before running a cmdlet or function.
The
$ConfirmPreferencevariable’s valid values are High, Medium, or Low. Cmdlets and functions are assigned a risk of High, Medium, or Low. When the value of the$ConfirmPreferencevariable is less than or equal to the risk assigned to a cmdlet or function, PowerShell automatically prompts you for confirmation before running the cmdlet or function.If the value of the
$ConfirmPreferencevariable is None, PowerShell never automatically prompts you before running a cmdlet or function.To change the confirming behavior for all cmdlets and functions in the session, change
$ConfirmPreferencevariable’s value.To override the
$ConfirmPreferencefor a single command, use a cmdlet’s or function’s Confirm parameter. To request confirmation, use-Confirm. To suppress confirmation, use-Confirm:$false.Valid values of
$ConfirmPreference:
- None: PowerShell doesn’t prompt automatically. To request confirmation of a particular command, use the Confirm parameter of the cmdlet or function.
- Low: PowerShell prompts for confirmation before running cmdlets or functions with a low, medium, or high risk.
- Medium: PowerShell prompts for confirmation before running cmdlets or functions with a medium, or high risk.
- High: PowerShell prompts for confirmation before running cmdlets or functions with a high risk.
–jeroen
Posted in .NET, CommandLine, Development, PowerShell, PowerShell, Scripting, Software Development | Leave a Comment »